Introduction to Web Archiving from the iSchool at UW-Madison
March 2021 to May 2021
Thanks to CLRC’s professional development grant, I was able to attend a 6-week online course on the topic of web archiving, which is gaining a lot more attention in the archives profession. I’m currently the Assistant Archivist for SUNY Upstate Medical University’s archives, and web archiving is an area that I didn’t have a lot of knowledge in, and this course was being offered through the University of Wisconsin-Madison’s iSchool. Web archiving is a topic that has become more acknowledged in just the past few years as institutions realize the importance of saving website content before it disappears or changes. But I think it’s slow to be acted on by many, as the ability to capture web content is often time consuming, and sometimes not an affordable option. Our own archive has not done any web archiving as of yet, and both my supervisor and I had limited knowledge on how it’s done and the options that are out there to archive web content. We felt this course would be a great opportunity to learn more and hopefully help us decide on our next steps as we navigate web archiving.
 Each week in the course we focused on a specific topic area. Since this was an introductory course to web archiving, we started with the basics so we could understand what it is and the terms associated with it. Web archiving is capturing portions of the web exactly as they are, so they can be preserved (with links intact) and used for future research. This is becoming more important for institutions as website content is constantly changed or lost, and this means access to important resources is also lost as well. There are different platforms that can be used to “crawl” these webpages and save the content. One of the most commonly used platforms is called Archive-It, which was created by the Internet Archive (which holds the largest collection of open access archived web content online).
Each week in the course we focused on a specific topic area. Since this was an introductory course to web archiving, we started with the basics so we could understand what it is and the terms associated with it. Web archiving is capturing portions of the web exactly as they are, so they can be preserved (with links intact) and used for future research. This is becoming more important for institutions as website content is constantly changed or lost, and this means access to important resources is also lost as well. There are different platforms that can be used to “crawl” these webpages and save the content. One of the most commonly used platforms is called Archive-It, which was created by the Internet Archive (which holds the largest collection of open access archived web content online).
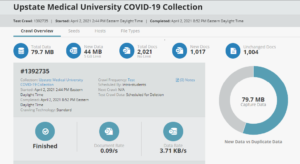
Archive-It is used by many institutions as it has good tech support and the capability to create unique collections easily. It is often seen as very user friendly compared to other platforms. This was the first platform we learned about and tested for our own collections we wanted to capture. The nice thing about using it for class purposes is you can run test-crawls for your collections first, which won’t take up any data. This way you can still see how your websites will be crawled, but without having to worry about taking up expensive data space. Before we chose our sites, we created a collections policy specific to web archiving, just like we would for our general archive. Making a policy helps to ensure you follow those guidelines for the content you are collecting. Once we knew what websites we wanted to crawl, (these were called “seeds”), we would submit these seeds to a test crawl and let Archive-It crawl those pages. Usually the crawl would take a couple days to capture the content. It was nice you could set the crawl and then let it do the work on its own. Once the crawl was finished, Archive-It gives you all the data on the pages crawled and you can see what pages worked, and those that didn’t.
Elise DeAndrea
Assistant Archivist, SUNY Upstate Medical University
Are you interested in being our next Professional Development Award recipient? Check out the award page for the rules & requirements!